




合作客户/
拜耳公司 |
同济大学 |
联合大学 |
美国保洁 |
美国强生 |
瑞士罗氏 |






相关新闻Info
推荐新闻Info
使用深度学习方法高通量预测代谢酶的 kcat,或揭开细胞工厂秘密
来源:ScienceAI 浏览 2515 次 发布时间:2022-09-14
酶周转数(kcat)是了解细胞代谢、蛋白质组分配和生理多样性的关键,但实验测量的kcat数据往往稀疏且嘈杂。
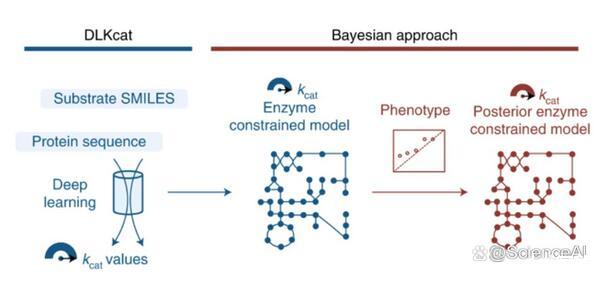
查尔姆斯理工大学(Chalmers University of Technology)的研究团队提供了一种深度学习方法(DLKcat),用于仅根据底物结构和蛋白质序列对来自任何生物体的代谢酶进行高通量kcat预测。DLKcat可以捕获突变酶的kcat变化并识别对kcat值有强烈影响的氨基酸残基。研究人员应用这种方法来预测300多种酵母物种的基因组规模kcat值。
此外,该团队设计了一个贝叶斯管道,以根据预测的kcat值参数化酶约束的基因组规模代谢模型。由此产生的模型在预测表型和蛋白质组方面优于先前管道中相应的原始酶约束基因组规模代谢模型,并使研究人员能够解释表型差异。DLKcat和酶约束的基因组规模代谢模型构建管道是揭示酶动力学和生理多样性的全球趋势,并进一步阐明大规模细胞代谢的宝贵工具。
该研究以「Deep learning-based kcat prediction enables improved enzyme-constrained model reconstruction」为题,于2022年6月16日发布在《Nature Catalysis》。

酶转换数(kcat)定义了反应的最大化学转化率,是了解特定生物体的新陈代谢、蛋白质组分配、生长和生理学的关键参数。酶数据库BRENDA和SABIO-RK中有大量可用的kcat值集合,然而,与现有的各种生物体和代谢酶相比,这些值仍然稀少,这主要是因为缺乏用于kcat测量的高通量方法。
此外,由于不同的测定条件(例如pH值、辅因子可用性和实验方法),实验测量的kcat值具有相当大的可变性。总之,稀疏的收集和相当大的噪声限制了kcat数据在全局分析中的使用,并可能掩盖酶进化趋势。
特别是酶约束的基因组规模代谢模型(ecGEM),其中全细胞代谢网络受到酶催化能力的约束,因此能够准确模拟最大生长能力、代谢变化和蛋白质组分配,特别依赖于基因组-缩放kcat值。在过去的十年中,ecGEM(或遵循酶约束概念的模型)已分别针对几种经过充分研究的生物体开发,包括大肠杆菌、酿酒酵母、中国仓鼠卵巢细胞和智人。由于kcat测量的局限性和依赖酶委员会(EC)编号注释来搜索这些已开发管道中的kcat值,为研究较少的生物体重建ecGEM或为多种生物体进行大规模重建仍然是一个挑战。
此外,即使对于那些经过充分研究的生物,kcat的覆盖范围也远未完成。在酿酒酵母ecGEM中,只有5%的酶促反应在BRENDA中具有完全匹配的kcat值。当数据缺失时,以前的ecGEM重建流程通常假设kcat值来自类似的底物、反应或其他生物,这可能导致模型预测偏离实验观察。明确要求获得大规模的kcat值以提高模型准确性并产生更可靠的表型模拟。
深度学习已被应用并在模拟化学空间、基因表达、酶相关参数(如酶亲和力和EC数)方面表现出出色的性能。此前,有研究人员采用机器学习方法,根据从蛋白质结构中获得的平均代谢通量和催化位点等特征来预测大肠杆菌kcat值。然而,这些特征通常很难获得,这使得这种方法只能应用于研究最充分的生物体,如大肠杆菌。
在这里,查尔姆斯理工大学(Chalmers University of Technology)的研究团队提出了深度学习方法DLKcat来预测所有代谢酶与其底物的kcat值,只需要底物SMILES信息和酶的蛋白质序列作为输入,从而为任何物种产生通用的kcat预测工具。
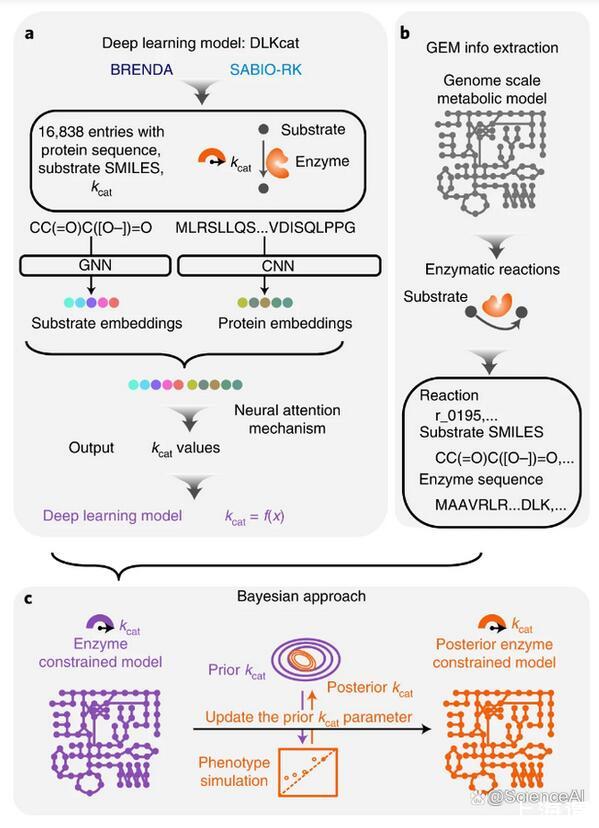
图示:用于ecGEM参数化的kcat深度学习。(来源:论文)
DLKcat可以捕获kcat向精确的单个氨基酸替代方向的变化,从而能够计算注意力权重,从而识别对酶活性产生重大影响的氨基酸残基。氨基酸取代是酶进化领域的一项强大技术,通常用于探测酶催化机制。特别是,大多数替代实验在底物结合位点区域进行诱变,因为假设结合区域将对催化活性产生很大影响。然而,据报道,偏远地区会对催化活性产生深远影响。
研究人员不仅确定了人PNP酶肌苷结合区域中氨基酸残基的高关注权重,而且还确定了具有高关注权重的各种非结合残基位点,这表明这些残基也可能对催化活性产生重大影响,值得进一步验证。DLKcat因此可以作为蛋白质工程工具箱的重要组成部分。
预测的基因组规模的kcat谱可以促进酶约束代谢模型的重建,从策划和自动生成的基本(非ec)GEM中。事实证明,深度学习预测的kcat过程比匹配来自BRENDA和SABIO-RK数据库的体外kcat值更全面但仍然实用;这在GECKO和MOMENT等原始ecGEM重建管道中很常见。
通过不依赖EC编号注释,DLKcat还能够预测同工酶特异性kcat值,而SMILES的使用避免了原始ecGEM重建管道可能遇到的GEM和BRENDA之间底物命名不统一的问题。随后可以通过贝叶斯方法将DL-ecGEM调整为现有的实验生长数据,该方法产生具有生理相关解空间的后均值ecGEM。结合起来,当前基于DLKcat的管道因此适用于几乎任何生物体的ecGEM重建,其中蛋白质序列FASTA文件和基本GEM可用。他们的管道因此提高了适用性,与以前构建的原始ecGEM相比,它甚至提高了具有酶促约束的反应数量。
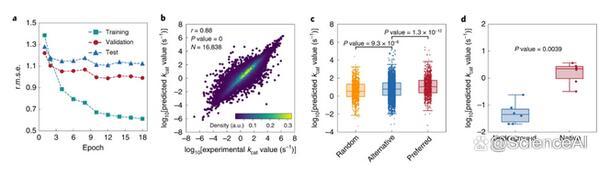
图示:kcat预测的深度学习模型性能。(来源:论文)
尽管基于DLKcat的管道产生的ecGEM性能优于原始ecGEM,但仍然存在各种挑战。例如,虽然深度学习模型可以将混杂酶的替代物与随机选择的底物区分开来,但它仍然预测了可能过高的随机底物的动力学活性水平。
这种行为可以通过负面数据的有限可用性来解释:酶-底物对没有产生催化作用的情况。增加对阴性数据集的报告,其中酶-底物对的未检测到的活性由酶数据库报告和收集,可以增强未来深度学习模型在定义真阴性方面的能力。
此外,DLKcat并未考虑pH和温度等环境因素的影响,但将DLKcat与其他新兴机器学习工具(例如酶的最佳温度预测)相结合,将有助于未来研究环境参数对酶活性的影响。
另一个挑战涉及涉及多种底物和由异聚酶复合物催化的反应。可以为此类反应定义的多底物SMILES和蛋白质序列都可以与DLKcat一起发挥作用,从而为一个反应产生多个预测的kcat值。目前在这些情况下,研究人员会选择最大kcat值,但最好设计一种方法来预测每种多底物和异聚酶的一个kcat值。
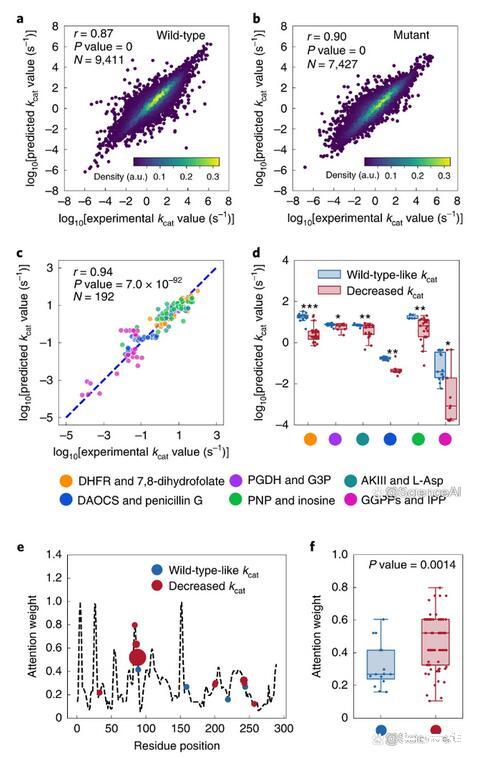
图示:用于预测和解释突变酶kcat的深度学习模型。(来源:论文)
此外,DLKcat衍生的DL-ecGEM和后验均值ecGEM继承了基本GEM的局限性,其中基于约束的建模的核心稳态假设允许人们确定代谢通量,但不容易考虑调节行为。虽然ecGEM极大地将基于约束的模型的解空间减少到细胞可行容量,但kcat并不是决定反应速率的唯一动力学参数,例如,亲和常数起着重要的作用。然而,由于基于约束的模型无法预测内部代谢物浓度,因此目前无法轻易考虑这些参数的影响。
尽管如此,kcat值也是其他资源分配模型中的重要参数,例如蛋白质组约束的GEM和代谢/大分子表达模型。尽管改进的预测和更多的应用,如何定义kcat值也仍然是重建这些模型的挑战。这种资源分配模型和ecGEM都认为细胞需要将其有限的蛋白质组分配到不同的途径以实现更快的生长或更好的适应度,而每个反应的蛋白质组成本同样由酶的通量和动力学速率定义。
因此,这些模型的代谢部分的深度学习预测kcat值可以提高其质量和性能,尽管无法从DLKcat获得在这些模型公式中确定的其他具有挑战性的动力学参数,例如核糖体催化率。此外,特别关注描述酶动力学的模型公式可以受益于深度学习预测的kcat值,因此DLKcat方法可以在建模领域找到广泛的应用。
总之,DLKcat产生了现实的kcat值,可用于指导未来的基因工程、了解酶进化和重建ecGEM以预测代谢通量和表型。除此之外,这种基于深度学习的kcat预测工具的许多其他潜在用途,例如基因组挖掘和全基因组关联研究分析中的工具。开发的自动贝叶斯ecGEM重建管道将有助于进一步用于ecGEM重建,用于组学数据合并和分析。
论文链接:https://www.nature.com/articles/s41929-022-00798-z